Implementation of nested set design of SQL with Java - Preorder Tree Traversal
Preface
Recently, we got a requirement for storage directories and files,the condition is,
- Input parameter is the path of the root directory which was unpacked.
- The files will not change nor update after unpacked.
The details of the requirement is,
- The directories and all its subdirectories and sub-files need to be parsed into a tree structure response to the front end.
- When the user clicks on each level of directory, we need to get the files in this directory and all its subdirectories for some business data statistics.
- We can only use the MySQL.(Can’t use a graph database.)
After research, the found that nested set design is well suited for such a scenario.1
Note - If graph databases are used in the project, graph databases are a better choice for handling complex hierarchical data.
It is hard to find ready-made code on the Internet that uses Java to implement this, and only found a project on github that implements part of the functionality. However, this project does not support MyBatis and I do not plan to adopt it, so I can only implement the nested set design by myself.
This article will briefly introduce the Nested Set Model Nested Set Model, details of how to use Java, from the table to the library to implement the nested set model.
The examples in this article use MySQL 8.0, JDK 8.
Nested Set Model
When faced with hierarchically structured data stores, such as catalogs,

We tend to use the scheme known as the neighboring table model with table field designs of approx:1
id, name, parentId
In the adjacency table, all data has a parentId field to store its parent node ID. if the current node is the root node, its parent node is NULL or -1. When traversing, you can use recursion to query the whole tree, but also easy to query the next level of nodes. It is also easy to add and delete. However, when the amount of data is large, querying the whole tree will affect performance, and even lead to memory overflow.
Therefore, in use, we usually use lazy loading to show the data one level at a time. Or limit the depth of the recursion to show only part of the data.
If the known data additions, deletions and changes are rare, the query performance requirements are relatively high, and like our needs, we need to check all the leaf nodes under a node, you can consider using the nested set model. The design of the nested set model is approximately:1
id, name, left_index, right_index, depth
In other words, this views the individual nodes as individual containers, with the child nodes inside the parent node and all nodes in the root node; represented in a picture as follows:

Then numbered from left to right, each container has a left and right two numbers, that is, for the left and right; represented by the picture as follows:
To make it easier to query the next level node and other nodes, a depth field can be added to indicate the depth.
At this point, the left and right values of each node can be obtained.
Below are just a few of the most commonly used SQLs. Other SQLs can be found in Managing Hierarchical Data in MySQL.
Implemented in Java
MySQL Table Design
1 | CREATE TABLE `file_nested_sets_demo` ( |
Constructing mapping entities
1 | /** |
Data number entry
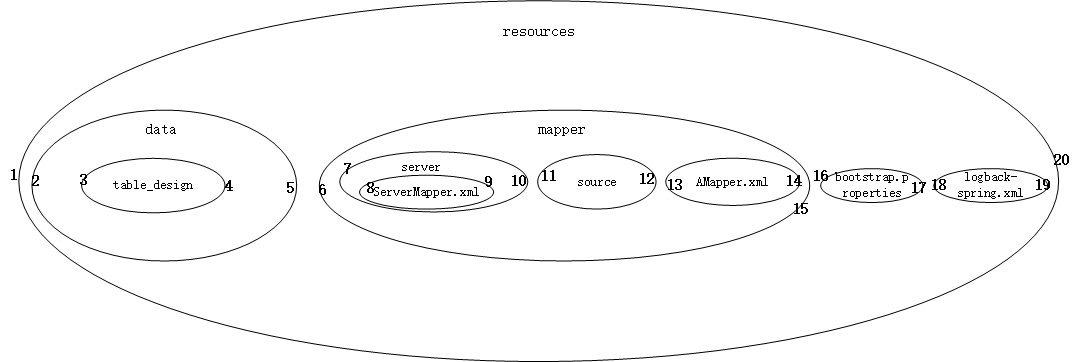
The input data is known to be a file path, and the path structure is the same as in the above figure, for example:1
2
3
4
5
6
7
8
9
10
11
12|== means folder; |-- means file.
|==resources
|==data
|--table_design
|==mapper
|==server
|--ServerMapper.xml
|==source
|--AMapper.xml
|--bootstrap.properties
|--logback-spring.xml
The expected output is:1
2
3
4
5
6
7
8
9
10
11depth left_index|||path|||right_index
0 1|||\resources|||20
1 2|||\resources\data||5
2 3|||\resources\data\table_design|||4
1 6|||\resources\mapper|||15
2 7|||\resources\mapper\server|||10
3 8|||\resources\mapper\server\ServerMapper.xml|||9
2 11|||\resources\mapper\source|||12
2 13|||\resources\mapper\AMapper.xml|||14
1 16|||\resources\bootstrap.properties|||17
1 18|||\resources\logback-spring.xml|||19
We can construct the data using the precedence traversal algorithm, traversing its children and assigning values from left to right, one layer at a time.
The following code uses a depth-first approach to traverse the directory and assign values, returning Map.
1 | public class NestedSetsUtil { |
Then just traverse the data from the NestedSetsUtil#dfs2NestedSets() response, assign it to FileNestedSetsDemo, and batch into the library.
Query data based on business requirements
Retrieve all child nodes of type file under a single path
1
2
3
4
5
6
7
8
9
10SELECT node.*
FROM file_nested_sets_demo AS node,
file_nested_sets_demo AS parent
WHERE node.depth = parent.depth + 1
AND node.left_index > parent.left_index
AND node.right_index < parent.right_index
AND node.tree_id = 1
AND parent.path = '\resources\mapper'
AND node.type = 'FILE'
ORDER BY parent.left_indexRetrieve all child nodes under a single tree
1
2
3
4SELECT node.*
FROM file_nested_sets_demo AS node
WHERE node.tree_id = 1
ORDER BY node.left_index
Extended Query Statements
- Retrieve direct child nodes under a single path
1 | SELECT node.* |
Note
The Java algorithms that can be executed can be found in GitHub