前言 最近有一个目录文件入库的需求,条件是:
入参是解压后的文件夹路径;
解压后的文件不存在变更及更新的情况。
需求详情是:
文件夹及其所有子目录和子文件,都需要解析成树结构响应给前端;
需要在点击每一级目录时,都拿到这个目录下所有文件(包括子目录下的文件)进行一些业务数据的统计;
只能使用关系型数据库MySQL。
经过调研 , 发现嵌套集设计 (译文1) (译文2) 很适合这样的场景。Note - 如果项目中用到或可以用图数据库,图数据库是处理复杂层次数据更好的选择。
互联网上很难找到使用Java实现的现成代码,只在github上找到一个项目 实现了一部分功能。但此项目不支持MyBatis,我不计划采用,因此只能自己实现嵌套集设计。
这篇文章会简单介绍嵌套集模型 Nested Set Model,详细介绍如何使用Java,从建表到入库实现嵌套集模型。
本文示例使用 MySQL 8.0、JDK 8
嵌套集模型 在面对分层结构数据存储时,例如目录,
我们往往采用被称为邻接表模型 (Adjacency List )的方案,表字段设计大约是:
在邻接表中,所有的数据均拥有一个parentId字段,用来存储它的父节点ID。当前节点为根节点的话,它的父节点则为NULL或者-1。在遍历时,可以使用递归实现查询整棵树,也可以方便地查询到下一级节点。增删也方便。但是当数据量较大时,查询整棵树会影响性能,甚至导致内存溢出。
如果已知数据增删改很少,对查询性能要求比较高、并且像我们的需求一样,需要查某节点下所有叶子节点,就可以考虑使用嵌套集模型了。嵌套集模型的设计大约是:
1 id, name, left_index, right_index, depth
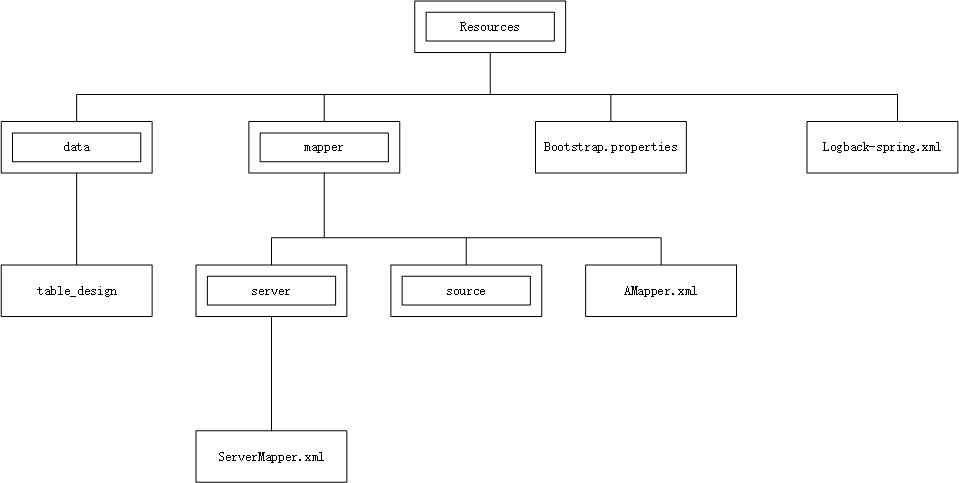
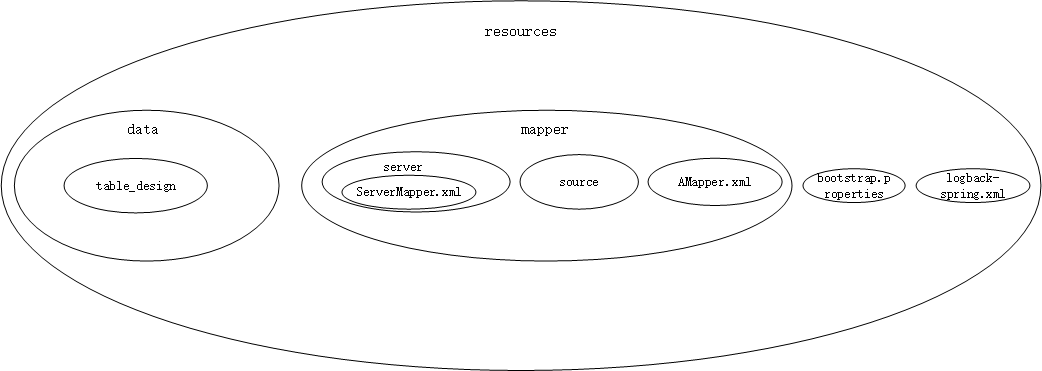
也就是把各个节点看做一个个容器,子节点在父节点内部,所有节点都在根节点中;用图片表示如下:
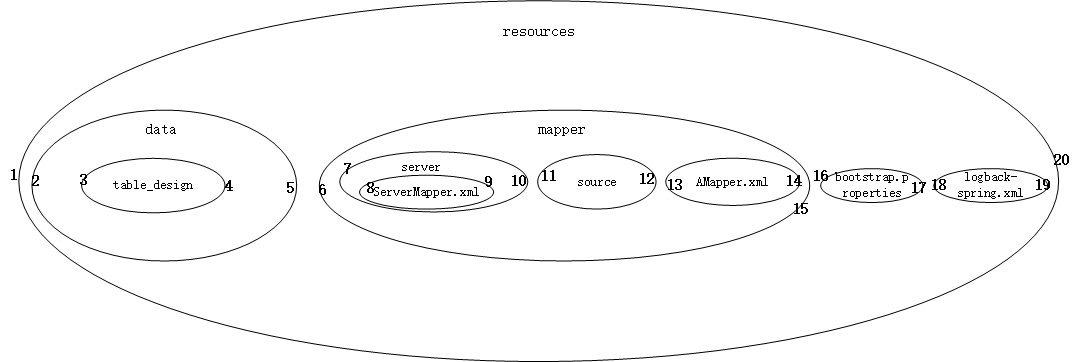
再自左向右编号,每个容器都有左右两个编号,即为left与right; 用图片表示如下:
为了方便查询下一级节点和其他节点,可以增加一个depth字段,用来表示深度。嵌套集设计 中查看.
使用Java实现 MySQL表设计 1 2 3 4 5 6 7 8 9 10 11 12 CREATE TABLE `file_nested_sets_demo` ( `id` varchar(100) NOT NULL COMMENT '文件ID,唯一标识', `path` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '文件完整路径', `type` varchar(100) DEFAULT NULL COMMENT '文件类型; Directory,File', `size` double DEFAULT NULL COMMENT '文件大小', `tree_id` bigint DEFAULT NULL COMMENT '每棵树的ID', `left_index` bigint NOT NULL COMMENT '左值', `right_index` bigint NOT NULL COMMENT '右值', `depth` bigint NOT NULL COMMENT '深度', PRIMARY KEY (`id`), KEY `idx_tree_id_indexes` (`tree_id`,`left_index`,`right_index`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='文件嵌套集表示例';
构建映射实体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class FileNestedSetsDemo { private String id; private String path; private String type; private Double size; private Long treeId; private Long leftIndex; private Long rightIndex; private Long depth; }
数据编号入库 已知输入的数据为文件路径,路径结构同上图,如:
1 2 3 4 5 6 7 8 9 10 11 |== 表示文件夹; |-- 表示文件。 |==resources |==data |--table_design |==mapper |==server |--ServerMapper.xml |==source |--AMapper.xml |--bootstrap.properties |--logback-spring.xml
需要的输出的数据是:
1 2 3 4 5 6 7 8 9 10 11 depth left_index|||path|||right_index 0 1|||\resources|||20 1 2|||\resources\data||5 2 3|||\resources\data\table_design|||4 1 6|||\resources\mapper|||15 2 7|||\resources\mapper\server|||10 3 8|||\resources\mapper\server\ServerMapper.xml|||9 2 11|||\resources\mapper\source|||12 2 13|||\resources\mapper\AMapper.xml|||14 1 16|||\resources\bootstrap.properties|||17 1 18|||\resources\logback-spring.xml|||19
我们可采用先序遍历算法构造数据,从左到右、一次一层,遍历其子节点并赋值。
NestedSetsUtil >folded 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 public class NestedSetsUtil { public static Map<File, NestedSetObj> dfs2NestedSets (File root) { if (root == null ) { return new HashMap <>(0 ); } long depth = 0L ; long index = 1L ; Deque<File> stack = new ArrayDeque <>(); stack.push(root); Map<File, NestedSetObj> map = new LinkedHashMap <>(); NestedSetObj rootObj = NestedSetObj.builder().path(root.getAbsolutePath()).depth(depth).left(index++).build(); map.put(root, rootObj); while (!stack.isEmpty()) { File cur = stack.pop(); depth--; File[] files = cur.listFiles(); if (files != null ) { for (File next : files) { if (!map.containsKey(next)) { depth++; stack.push(cur); depth++; stack.push(next); NestedSetObj obj = NestedSetObj.builder().left(index++).path(next.getAbsolutePath()).depth(depth).build(); boolean leaf = !next.isDirectory(); boolean emptyDirLeaf = next.listFiles() != null && next.listFiles().length == 0 ; if (leaf || emptyDirLeaf) { obj.setRight(index++); } map.put(next, obj); break ; } } long min = Long.MAX_VALUE; for (File file : files) { NestedSetObj childObject = map.get(file); if (childObject == null ) { min = 0L ; break ; } min = Math.min(min, childObject.getRight()); } if (min > 0L && Long.MAX_VALUE != min) { NestedSetObj curObj = map.get(cur); if (curObj.right == 0L ) { curObj.setRight(index++); } } } } rootObj.setRight(map.size() * 2L ); return map; } public static class NestedSetObj { private long left; private long right; private long depth; private String path; } }
接着把 NestedSetsUtil#dfs2NestedSets() 响应的数据遍历,赋值给FileNestedSetsDemo,批量入库即可。
根据业务需求,查询数据
检索单个路径下的所有类型为文件的子节点
1 2 3 4 5 6 7 8 9 10 SELECT node.* FROM file_nested_sets_demo AS node, file_nested_sets_demo AS parent WHERE node.depth = parent.depth + 1 AND node.left_index > parent.left_index AND node.right_index < parent.right_index AND node.tree_id = 1 AND parent.path = '\resources\mapper' AND node.type = 'FILE' ORDER BY parent.left_index
检索单个树下的所有子节点
1 2 3 4 SELECT node.* FROM file_nested_sets_demo AS nodeWHERE node.tree_id = 1 ORDER BY node.left_index
扩展查询语句
检索单个路径下的直接子节点1 2 3 4 5 6 7 8 9 SELECT node.* FROM file_nested_sets_demo AS node, file_nested_sets_demo AS parent WHERE node.depth = parent.depth + 1 AND node.left_index > parent.left_index AND node.right_index < parent.right_index AND node.tree_id = 1 AND parent.path = '\resources\mapper' ORDER BY parent.left_index
Note 可以执行的Java算法见 github